Introduction
Unlike most mainstream sports that enjoy centralized national leagues, millions of dollars that can be spent to collect and organize data efficiently, and fans that would love to spend extra time tracking player statistics, Jiu-Jitsu continues to be very much a grassroots effort with a scattered data landscape.
As such, finding reliable and easy to access datasets are few and far between. This project demonstrates how to utilize Python and the Beautifulsoup library to collect over 50,000 match results from the BJJHeroes website.
Beautifulsoup Explained
Beautifulsoup is an html parsing library.
What that means is that from the requests library, we can use the get function to obtain access to the website within a python notebook. Then, using the Beautifulsoup library, we can parse through the html code of a website to obtain the information we are looking for.
Importing Packages and Accessing Website
To begin, I am:
- Importing requests to access the website
- Importing pandas
- Declaring the website as a variable r so that we can access it
- Showing the first 500 characters of the html website to confirm we have access to it
import requests
import pandas as pd
from bs4 import BeautifulSoup
r = requests.get('https://www.bjjheroes.com/a-z-bjj-fighters-list')
# Print the first 500 characters of the HTML
print(r.text[0:500])
<head dir="ltr" lang="en-US">
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<link href="//www.google-analytics.com" rel="dns-prefetch">
<meta name="viewport" content="width=device-width, initial-scale=1.0, user-scalable=yes" />
<link rel="pingback" href="https://www.bjjheroes.com/xmlrpc.php">
<link rel="icon" id="favicon" type="image/png" href="https://www.bjjheroes.com/wp-content/uploads/2020/03/favicon-16x">
Finding the 'Tags' we are looking for
Now that we know we are accessing the website html, here is an example of using the parser to return parts of the html website. We will assign the variable tag the title tag from the website.
soup = BeautifulSoup(r.text, 'html.parser')
tag = soup.title
tag
Looking at the page website we see that the First Name, Last Name, Nickname, and Team are stored in a dataframe style format.
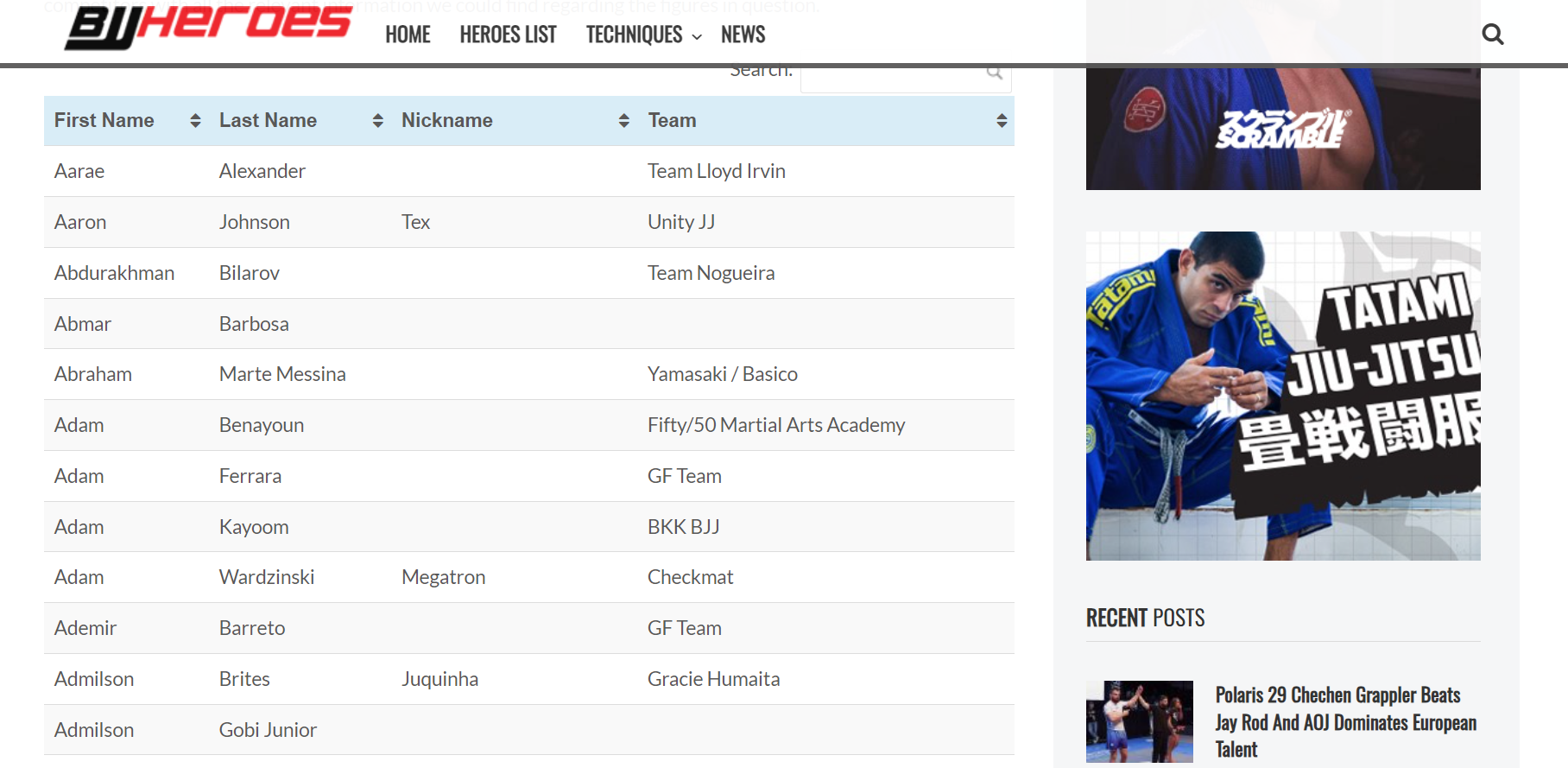
This table is stored as a Table Row (tr) class
Within a tr, the row and column entries are stored as a Table Data (td) class.
We can use the .find_all() method to return all entries that have the td class.
tag = soup.find_all("td")
print('First 20 entries')
tag[:10]
<td class="column-1"><a href="/?p=8141">Aarae</a></td>,
<td class="column-2"><a href="/?p=8141">Alexander</a></td>,
<td class="column-3"></td>,
<td class="column-4">Team Lloyd Irvin</td>,
<td class="column-1"><a href="/?p=9246">Aaron</a></td>,
<td class="column-2"><a href="/?p=9246">Johnson</a></td>,
<td class="column-3"><a href="/?p=9246">Tex</a></td>,
<td class="column-4">Unity JJ</td>,
<td class="column-1"><a href="/?p=8494">Abdurakhman</a></td>,
<td class="column-2"><a href="/?p=8494">Bilarov</a></td>
What can we learn from the above output?
- Each name contains a link (a href="...") , which we can use to get to each individual athletes stats page
- Each entry follows the same format, so we can reliably iterate through and store this information in a dataframe